
Дорогие друзья, сегодня я хочу поделиться своими мыслями о том, чтобы я хотел улучшить в Яндексе и Google.
Я выскажу свое мнение с точки зрения обычного владельца сайта.
Содержание
Определение первоисточника
Многие вебмастера сталкиваются с проблемой, когда поисковые системы некорректно определяют первоисточник.
Например, владелец сайта пишет качественные и интересные статьи, или заказывает их у копирайтера. А другие сайты просто копируют материалы и публикуют у себя, часто без ссылки на первоисточник.
Даже если и размещают ссылку на источник, есть вероятность того, что сайты, скопировавшие статьи, будут находиться выше, чем сайт, на котором этот контент появился впервые.
Да, в Яндекс Вебмастере есть инструмент "Оригинальные тексты". В Гугл подтвердить авторство можно через соцсеть Google+. Можно указать автора с помощью микроразметки schema.org через itemprop="author".
На практике это не решает проблему. Решение должно быть реализовано на уровне алгоритмов поисковых систем.
Большое количество сайтов страдают от несправедливости в плане определения первоисточника. Я встречал много примеров, когда используются "Оригинальные тексты" Яндекса, подтверждено авторство в Гугл Плюсе и сделана микроразметка, но конкуренты, скопировавшие статьи, ранжируются выше первоисточника. Бывает, что даже переписывание оригинальных текстов не помогает.
Другой пример - более трастовый ресурс публикует статью с первоисточника, размещая ссылку на него, и при этом ранжируется выше.
Конечно, можно сказать, что для поисковиков главное, чтобы материал был релевантен, полезен для посетителей и отвечал на их вопрос. Но ситуация, когда на разных сайтах размещен один и тот же текст, и при этом первоисточник находится ниже сайтов, которые просто скопировали с него статью, является неправильной.
Думаю, что сайты, которые публикуют оригинальный и полезный контент, составляют всего несколько процентов от общего числа ресурсов как в рунете, так и в англоязычном интернете. Все остальные либо просто копируют, либо переписывают их материалы.
Я считаю, что если бы сайты, которые производят уникальные и интересные тексты, получали преимущество в ранжировании, а ресурсы, которые размещают копированные или переписанные материалы, пессимизировались, то это было бы одним из самых эффективных решений проблемы с качеством поисковой выдачи.
Естественно, сама по себе уникальность текстов не является гарантией, что материал действительно интересен и полезен, так как тексты могут просто переписать другими словами.
Но я уверен в том, что для поисковых систем не составляет проблемы определить сайты, на которых публикуются оригинальные тексты.
🔥 Кстати! Я провожу платный курс по продвижению англоязычных сайтов SEO Шаолинь seoshaolin.com. Для читателей блога я делаю хорошую скидку. По прокомоду "блог" тариф Про стоит не 50, а 40 тыс. рублей. Тариф Лайт не 25, а 20 тыс. рублей. Тариф Команда не 75, а 60 тыс. рублей. Пишите мне в Telegram @mikeshakin.С учетом анализа поведения посетителей на странице, насколько активно они ее комментируют и делятся в социальных сетях, можно без проблем определять именно те сайты, которые производят действительно полезный и уникальный контент.
Как только схема "Копируешь – не будет посетителей, пишешь качественные статьи – будут посетители", дойдет до широких масс, то это в корне изменит ситуацию с качеством сайтов.
Но пока это не реализовано на уровне алгоритмов Яндекса и Google, проблема будет оставаться.
Техподдержка
Я считаю, что в Яндексе и Google нужна полноценная техподдержка.
В Google вся поддержка осуществляется через форум. Получение ответов может занять несколько дней, некоторые вопросы остаются без ответов.
В Яндексе ситуация намного лучше. Техподдержка у Яндекса есть, но во многих случаях переписка не дает даже приблизительной информации о том, как исправить ситуацию с сайтом.
Я понимаю, что у поисковых систем своя политика, и никто не будет конкретно писать, что именно не так с сайтом и почему на нем понизилась посещаемость, так как особенности алгоритмов ранжирования – тайна за семью печатями. Да и раздувать штат никто не будет.
Но хотя бы приблизительные советы, которые могут исправить ситуацию, вполне можно давать.
Как вариант, чтобы не создавать нагрузку на сотрудников техподдержки и не увеличивать штат, для многих случаев можно создать ботов техподдержки, как примерно это реализовано у ботов в Telegram.
Например, с помощью цепочки вопросов бот может давать вебмастеру адрес страницы на его сайте, которая вызвала проблему с попаданием под фильтр. А дальше вебмастер изучит проблемную страницу и исправит ее, о чем сможет сообщить боту техподдержки через цепочку вопросов. Это значительно ускорит и выход сайтов из-под фильтров.
В Яндексе нужен аналог DMCA жалоб
Такой инструмент необходим, чтобы владельцы сайтов могли сообщать о нарушении своих авторских прав.
Например, написали вы книгу или создали видеокурс. Хотите заработать на своем труде. Ваши материалы воруют и размещают на разных форумах и варезниках для бесплатного скачивания, или в виде складчин.
В Google в таких случаях можно подать DMCA жалобу, и сайт, который своровал ваш материал, перестанет отображаться в результатах поиска по нужному запросу. Этот процесс занимает немного времени, бывает, что через 4 часа сайт удаляют из выдачи.
Причем для каждого ресурса Google мониторит число DMCA жалоб. Если их много, то сайт вполне может попасть под фильтр за многократное нарушение авторских прав, вплоть до полного удаления из индекса.
В Яндексе очень не хватает такого инструмента. Было бы замечательно, если бы он появился.
В Яндексе нужен инструмент отклонения ссылок
В свете борьбы с некачественными ссылками в Яндексе очень нужен инструмент для отклонения ссылок, по аналогии с Google Disavow Tool, в который вебмастера могли бы загружать списки ссылок на свои сайты, которые они хотели бы не учитывать.
Бывают ситуации, когда конкуренты или недоброжелатели размещают на сайт множество ссылок с мусорных ресурсов (заспамленных форумов, комментариев, гостевых книг и т.д.
Алгоритм Google Penguin уже не учитывает такие ссылки.
Для полной уверенности вебмастеров, что их сайты не пострадают от некачественных ссылок, в Google несколько лет назад реализовали инструмент Disavow Tool.
Было бы здорово, если бы в Яндексе сделали такой же инструмент.
К тому же это отличная возможность – по сути, вебмастера будут добровольными асессорами, которые будут формировать большую базу некачественных ссылок, которая может пригодиться для обучения поисковых алгоритмов. Конечно, определенный процент ссылок в такой инструмент будет добавлен недоброжелателями или конкурентами, и они будут качественными, но этот вопрос можно решить.
Без этого инструмента в Яндексе у многих владельцев сайта остается проблема, что делать с некачественными ссылками. Удалять ссылки – за это многие вебмастера требуют деньги. На мой взгляд, это вообще нонсенс – сначала брать деньги за размещение ссылки, потом за ее удаление.
Да и удалить ссылки с некачественных ресурсов можно далеко не всегда.
Дубли и малоинформативные страницы
Многие движки сайтов генерируют дубли страниц, а также малоинформативные страницы (архивы по годам, месяцам, архивы категорий, тегов и т.д.).
Поисковые системы знают об этих особенностях.
Но почему тогда поисковые роботы сами не определяют дубли страниц популярных движков и во многих случаях продолжают их индексировать?
Ведь на это затрачиваются огромные ресурсы – тратится краулинговый бюджет при индексации сайта, базы данных поисковиков значительно увеличиваются в размерах за счет ненужной информации, плюс малоинформативные страницы могут попадать в результаты выдачи вместо нормальных страниц с полезной информацией.
Почему вебмастерам надо самим заботиться о том, чтобы поисковые роботы не индексировали ненужные страницы и разделы? Для роботов поисковых систем не составляет никаких проблем сделать это нужным образом.
Для многих владельцев сайтов и блоггеров закрыть дубли и ненужные страницы от индексации - не такая уж простая задача. Многие просто не могут проделать необходимые действия.
В тех случаях, когда владелец сайта захочет открыть для индексации определенные страницы или разделы, это можно реализовать через панели вебмастеров.
Яндексу не хватает рейтинга звезд в выдаче
У некоторых сайтов звезды рейтинга, реализованные через микроразметку schema.org/AggregateRating, в выдаче Яндекса уже выводятся:
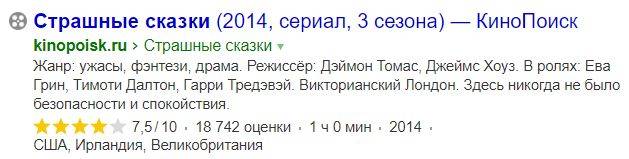
Но пока вывод звезд рейтинга встречается очень редко. Даже если сделать все правильно, то вероятность того, что звезды будут выводиться в выдаче Яндекса, очень мала.
А ведь оценка страницы пользователями является отличным показателем того, насколько им понравился материал. И такую информацию имеет смысл выводить в результатах поиска почаще.
Год назад техподдержка Яндекса отвечала, что пока это лишь эксперимент и такие рейтинги отображаются не у всех сайтов. Со временем списки сайтов будут расширяться, одни сайты будут добавляться, другие - отключаться.
С того времени ситуация не изменилась. Было бы замечательно, если бы звезд в выдаче Яндекса стало больше.
https
Переход сайтов на защищенный протокол https часто связан с различными проблемами.
Даже если сделать все правильно, то у многих сайтов наблюдается понижение позиций и посещаемости. В большинстве случаев это имеет временный характер, и затем все восстанавливается.
Конечно, есть сайты, которые переходят без каких-либо проблем, но случаев с негативными последствиями намного больше.
Я считаю, что при массовом переходе сайтов на https поисковым системам имеет смысл подкорректировать свои алгоритмы таким образом, чтобы версии сайта на http и https не были разными ресурсами.
Это позволит свести к минимуму возможные потери трафика для сайтов, которые переходят на защищенный протокол.
Вот такие у меня мысли по поводу того, что можно улучшить в поисковых системах 🙂 .
Если у вас есть свои мысли, то буду рад, если поделитесь ими в комментариях.
Михаил Шакин
На десерт сегодня видео о том, как собирают Порше 911. Никакой музыки или закадрового голоса, что сейчас редкость. Настоящее видео для релаксации 🙂 :
 Меня зовут Михаил Шакин, я автор этого блога, занимаюсь SEO с 2006 года. Вы можете заказать у меня
Меня зовут Михаил Шакин, я автор этого блога, занимаюсь SEO с 2006 года. Вы можете заказать у меня
Аж порш захотелось))
Михаил, вы уже переводили сайты на https? И второй вопрос, что думаете про закон о персональных данных?
Влад, да, несколько перевел. Раз есть новый закон, то его надо соблюдать.
А сами делали или заказывали? Может порекомендуете специалиста?
Сам делал. Сейчас в интернете много подробных инструкций и чеклистов по переходу на https.
Здравствуйте! Недавно переводил один не большой сайт на https, за 20 дней в Яндекс появилось сообщение что главное зеркало https. В Google с этим проще и быстрей.
Михаил подскажите пожалуйста, если в Google webmaster в одном аккаунте есть два по сути одинаковых сайта, один с посещаемостью и под русскоязычную аудиторию .ru, второй под англоязычную .us (но посещаемость сейчас с десяток человек). Нужно ли убирать код Google аналитики с англоязычного сайта, убирать связь с Google webmaster и создавать новый аккаунт Gmail и подключать новые коды Google аналитики и связывать с Google вебмастером? Или это вовсе несущественно?
Здравствуйте, Илья! Да, в Google такое иногда бывает.
По Google Webmaster - это несущественно. Можно держать оба этих сайта на одном аккаунте вебмастера и аналитики.
Спасибо вам
Михаил, как вы думаете стоимость протокола https упадёт?
Вполне возможно. Волна ажиотажа спадет, и цена может понизиться.
Ясно, тогда не стоит спешить. Говорят, что после перехода на https на сайте могут появится некоторые изменения с плагинами и самим оформлением сайта. Это правда?
Да, некоторые плагины могут перестать работать, если их разработчики не внесли необходимых изменений. Но у большинства популярных плагинов таких проблем нет.
Полностью согласен со всеми пунктами, представленными в статье. Я относительно недавно стал интересоваться всей этой темой поисковой оптимизации, поэтому было вдвойне интересно прочитать.
+1
Доска бесплатных объявлений Украины."DoskaUA" https://www.doskaua.com.ua/
– это крупнейший портал, где можно продать, обменять и купить почти все, что угодно! Кроме того, здесь можно найти работу или найти сотрудников в Вашу компанию. Это наиболее эффективный и простой способ приобрести все, что Вам нужно, и продать то, что Вам уже не нужно. На нашей доске Вы можете быстро и просто дать бесплатное объявление, и абсолютно бесплатно получить информацию о товарах и услугах, которые Вас интересуют.
Михаил, добрый день! Подскажите пожалуйста. Заметил в вебмастере Google что на англоязычный блог на одну статью появилось более двух тысяч ссылок со 170 доменов и их поддоменов (в среднем по 10-40 поддоменов), при переходе на эти урл на поддоменах идет 301 редирект на статью на сервис по накрутке лайков в Facebook.
Вероятно это спам ссылки. Позиции в течении месяца частично понизились также и на других страницах блога. Сегодня создал список 170 доменов и отправил их в Google Disavow Tools.
Или правильней будет создавая список ссылок для отклонения указывать полный урл страниц с поддоменами? Будет ли Google применять и игнорировать ссылки с поддоменов если в списке указаны только домены?
Михаил, добрый день! Подскажите пожалуйста. Заметил в вебмастере Google что на англоязычный блог на одну статью появилось более двух тысяч ссылок со 170 доменов и их поддоменов (в среднем по 10-40 поддоменов), при переходе на эти урл на поддоменах идет 301 редирект на статью на сервис по накрутке лайков в Facebook.
Вероятно это спам ссылки. Позиции в течении месяца частично понизились также и на других страницах блога. Сегодня создал список 170 доменов и отправил их в Google Disavow Tools.
Или правильней будет создавая список ссылок для отклонения указывать полный урл страниц с поддоменами? Будет ли Google применять и игнорировать ссылки с поддоменов если в списке указаны только домены? https://uploads.disquscdn.com/images/22575c7761675eeda78adee14fa5107edfbb993856da59d11673b822c89a6193.jpg
Здравствуйте, Илья! Вы правильно делаете. Полный адрес страниц указывать не нужно, достаточно домена. Если ссылка с поддомена, то лучше указать поддомен.
Почти все спам-ссылки с поддоменов. При нажатии на url идет 301 редирект на статью на сервис по накрутке лайков в Facebook.
В созданном файле для загрузки в Disavow Tool писал только домены, без поддоменов. Просто не уверен как правильней, достаточно ли указания только домена, без поддоменов . Фото добавил.
Если так не достаточно для Google, то дописывать поддомены вместо домена или оставить и домен и дописывать поддомены (поддоменов штук 600-700)
https://uploads.disquscdn.com/images/12cb8b2fd2170e9d7edb90673bd700ae846c071d08b11e3c6840061ff7638baf.jpg
Я бы дописал все поддомены вместо доменов. И домен оставил был.
Так понял что лучше оставить домены и дописать поддомены, вот так: https://uploads.disquscdn.com/images/314665246c6732b15d287483dc107d039a53b708d328edb05180e5f6a804b9fe.jpg
Чувствую предстоит еще пол дня ручного перебора и правок)
Михаил, большое Спасибо!
Да, именно так я и имел в виду. Для ускорения можно использовать автозамену в Excel.
Заменить все https:// на domain: получилось, а как оставить из всех поддоменов один, и убрать остальную часть url после поддомена это пока загадка
Сначала можно убрать хвост урлов поочередно по доменным зонам, например, сделать автозамену ".science/*" на ".science", ".com/*" на ".com" и т.д.
После этого просто удалить дубликаты в колонке получившихся адресов, и все дублирующиеся поддомены будут удалены, кроме одного.
Получилось!!! Благодаря вашей рекомендации по автозамене почистил хвосты url. Дубли поддоменов исчезли при импорте в Key Collector. Осталось из 2300 урл 637 поддоменов. Нагуглил как убрать дубли в Excel для проверки автоочистики в Key Collector, сошлось! Пересмотрел все url, убрал из списка нормальные url с международных доменов. Добавил поддомены в список Disavow links сразу после целого списка доменов (и комментария после #). Не группировал домен, а после все его поддомены.
Что интересно, после удаления и загрузки нового файла уже пишется не 170 доменов, а 805 доменов (то есть получается 170 доменов + 635 их поддоменов, а Disavow tools пишет что это все домены). Добавлял их через domain: (может из-за этого) . Надеюсь так будет надежней и лучше.
Михаил, огромное спасибо!
https://uploads.disquscdn.com/images/0d7a153c8d2a95feb8d74fec36a7d4ddcf2dd83a43cf889f8699e0566fb2a4a4.jpg
Пожалуйста, Илья! Вы все правильно сделали.